




I. Programmation concurrente▲
I-A. Définition▲
Une tâche est un flot d'exécution (une séquence de code)
exécuté sur un équipement particulier (PC, PDA, imprimante, ...)
à l'intérieur duquel l'ordre d'exécution des instructions
élémentaires est total et déterminé par les paramètres d'entrées :
les instructions se suivent invariablement les unes après les autres
dans le contexte d'exécution de la tâche.
Le multitâche consiste pour un système à pouvoir
dérouler plusieurs tâches simultanément, c'est à dire
pour lesquels l'ordre de déroulement des différents flots n'est
pas total entre eux. Cet ordre peut être perturbé selon
deux axes :
- Répartitions de plusieurs tâches sur une même ressource physique : le système accorde du temps à une tâche, puis l'interrompt, change le contexte vers une autre tâche à qui est accordée du temps, et ainsi de suite ;
- Déroulement de plusieurs tâches sur des ressources physiques distinctes : plusieurs tâches se déroulent simultanément sur des ressources physiques différentes.
Le concepteur d'une tâche ne sait pas à priori où et quand
son exécution va être interrompu au profit d'une autre tâche
ni si une autre tâche est exécutée sur une autre ressource
matériel en même temps.
La programmation concurrente recouvre les développements
de systèmes faisant intervenir du multitâche.
Selon ce que recouvre le système,
le multitâche peut mettre en oeuvre plusieurs équipements et/ou
ne concerner qu'un seul d'entre eux. A chaque granularité,
ses applications, ses mises en oeuvre, ses problèmes et
ses solutions. Nous allons présenter globalement les
différents niveaux des systèmes multitâches pour nous
concentrer ensuite sur le niveau du thread.
I-B. Un système - des équipements▲
Le niveau le plus haut de la programmation concurrente est donné par un système dont les différentes tâches sont réparties sur des équipements différents : plusieurs PC, des PC et des équipements annexes. Ce sont des systèmes où plusieurs programmes s'exécutent sur des machines différentes et interagissent entre eux pour fournir le service souhaité :
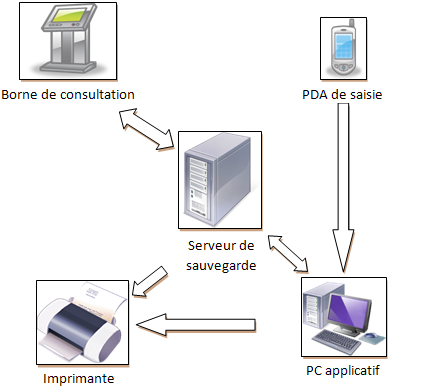
Chaque équipement peut avoir la responsabilité de tâches
bien définies et les exécute dans le cadre de son
environnement. Les différents équipements se sollicitent
mutuellement via des schémas transactionnels complets
(requête/réponse) ou non (message)
en s'appuyant sur des protocoles avec des niveaux d'abstraction
différents : TCP/IP, ODBC, RPC (Remote Procedure Call),
CORBA, DCOM, etc.
Citons quelques exemples :
- Web : des serveurs HTTP tournent sur des machines dédiées et des clients web (Firefox, Internet Explorer, ...) tournent côté client. Le client interroge le serveur Web pour une ressource, le serveur construit la réponse, la renvoie au client et finalement le client la traite pour la proposer à l'utilisateur ;
- Mail : idem que précédent : un serveur mail tourne sur une machine dédiée qui se charge de recevoir les mails, de les garder puis les transmettre au client lorsque celui-ci le demande. Le client mail permet de récupérer, lire et envoyer les messages depuis un PC ;
- Restaurant : le serveur saisie votre commande sur un équipement de type PDA, cette commande est transmise à un PC qui assure la facturation, gère les stocks et envoie des commandes vers le serveur des fournisseurs ;
- Informatique distribuée (grille, cluster, ...) : des calculs sont distribués sur plusieurs PC ;
- SGBD : le SGBD présent sur le serveur regroupe les données et gère les transactions; les clients émettent des requêtes vers le serveur pour afficher des vues sur les données ou en modifier le contenu ;
- ...
I-C. Le multitâche dans un seul équipement▲
Les systèmes d'exploitation actuels des PC sont tous multitâches. Vous pouvez surfer avec votre navigateur préféré tout en compilant votre dernier projet C++. Les O.S. spécifiques (en général pour l'embarqué) proposent souvent des architectures multitâches. Les O.S. mettent en oeuvre un ordonnanceur chargé de répartir les différentes tâches sur les ressources matérielles disponibles pour donner l'illusion d'un déroulement simultané. Le nombre de tâches étant le plus souvent supérieure au nombre de coeurs disponibles, l'O.S. découpe le temps processeurs et le distribue sur chaque tâche en basculant les contextes d'exécution. Ceci est évident sur un système à un seul coeur partagé par l'O.S. et les différentes tâches. Mais cela s'applique également sur les systèmes multicoeurs où cependant plusieurs tâches peuvent effectivement se dérouler en même temps sur des coeurs différents :
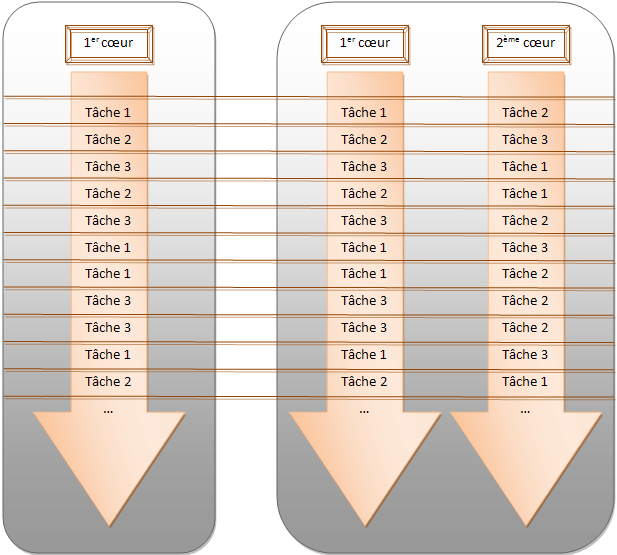
Le graphe ci-dessus n'a qu'un objectif d'illustration : nous avons choisi de mixer indifféremment les tâches sur les coeurs ce qui n'est pas forcément vrai. L'idée n'en reste pas moins valide.
Les premiers systèmes multitâches pour PC (par exemple,
Windows 3.1) proposaient un système multi-tâche collaboratif :
chaque tâche devait donner la main explicitement au
système pour permettre à l'ordonnanceur de dérouler une
autre tâche. Aujourd'hui, ces systèmes ont fait place
au multitâche préemptif : le système d'exploitation prend
seul l'initiative de suspendre une tâche pour permettre à
une autre de se dérouler selon l'algorithme de l'ordonnanceur.
Cette gestion est transparente pour le développeur d'un
programme. Il n'a plus à se soucier de rendre régulièrement
la main à l'OS et en contre partie ne doit pas faire d'hypothèse
sur le moment où il est suspendu au profit d'une autre tâche.
Dans ce cadre, on appelle opération atomique une opération
ou une séquence d'opérations dont l'exécution
n'est pas interrompue par le changement de contexte vers une
autre tâche.
L'O.S. peut prévoir des priorités accordées
aux différentes tâches. Les tâches les plus prioritaires
se voient accordées du temps CPU plus souvent que les
tâches non prioritaires. L'utilisation des priorités ne
peut se faire qu'en connaissance de l'algorithme de
séquencement mis en oeuvre. Ainsi, sous Windows, attribuer
à une tâche une priorité extrêmement élevée peut amener le
système à ne plus donner du temps CPU à des tâches moins élevées
cassant ainsi les bénéfices du multitâche, la tâche à la
priorité très élevée gardant en permanence la main.
De façon plus général, l'algorithme d'ordonnancement utilisé
par le système est souvent assez complexe, tient compte de
divers paramètres (priorités, architecture multiprocesseur,
affinités...) et met en oeuvre des stratégies pour éviter
les blocages induits par l'ordonnanceur (les Priority Boosts
ou Priority Inversion, par exemple). Il est par
conséquent assez délicat de prévoir finement le scénario
d'ordonnancement des tâches à un moment donné. Jouer avec
ces paramètres peut s'avérer assez dangereux en l'absence
d'une connaissance maîtrisée de l'O.S. et de sa stratégie
d'ordonnancement.
I-D. Multiprocessus▲
Un système multiprocessus orchestre plusieurs applications concurrentes au sein du même équipement. Un processus se caractérise par le caractère fortement privée de la mémoire physique à laquelle il accède. Il s'agit bien de l'élément déterminant, chaque processus a des zones mémoires physiques distinctes : (1)(2)
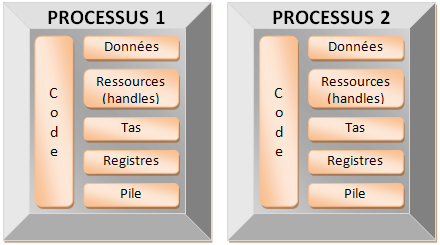
Une application ne peut accéder
aux zones mémoires d'une autre application. Les mécanismes
d'échanges de données et de synchronisation sont contraints
par cette étanchéité. En revanche, cela garantie
qu'une application ne pourra corrompre directement les
données d'une autre application.
L'échange et la synchronisation entre différents processus
d'un même équipement peut s'opérer aussi via des interfaces
avec des niveaux d'abstractions différents : ODBC, IPC, COM,
pipes, mémoire partagée, fichiers, etc.
Quelques exemples de système multiprocessus :
- un service de journalisation utilisé par d'autres applications ;
- un serveur de base de données utilisé comme dépôt local et interrogé par une application d'affichage ;
- un I.D.E orchestrant un éditeur de code, un compilateur, un analyseur de code, un debugger ;
- ...
I-E. Qu'est-ce qu'un thread ?▲
Un processus contient au moins un thread : une suite
d'instructions déroulées séquentiellement.
La littérature francophone emploie parfois le terme de
processus léger (le terme anglo-saxon de 'light-weight process'
peut recouvrir un sens légèrement différent).
Le multithreading permet d'exécuter plusieurs séquences
d'instructions parallèlement les unes aux autres dans le
cadre d'un processus. Les threads d'une même application
partagent entre eux une partie de la mémoire du processus.
Ils peuvent échanger des informations via des variables. Cela
induit des contraintes sur la façon de gérer correctement
ces échanges, comme nous le verrons plus loin.
Fondamentalement, la différence entre un thread et un
processus est bien cette séparation de la mémoire entre deux
processus et son partage entre deux threads. Les threads
d'un même processus partagent les variables globales, le tas,
les handles de ressources, etc... Ils ont leur propre
contexte de registre et leur propre pile, ce qui est
nécessaire à l'exécution des séquences d'instructions.
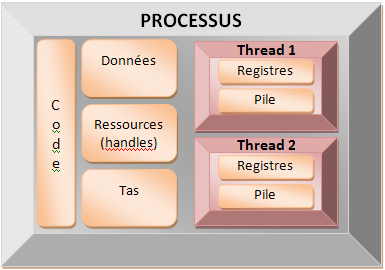
Pourquoi préférer un système multithread à un système multiprocessus ? Il ne s'agit pas de préférer l'un à l'autre. Chacun ayant des domaines d'applications différents. Les systèmes multiprocessus offrent un cloisonnement plus fort des différents services et, en général, les durées de vie de chaque processus est indépendant des autres composants du système. Le multithread se différencie du multiprocessus par la facilité du partage des données puisque la mémoire virtuelle est la même et par la plus grande rapidité de bascule d'un thread à un autre (seule la pile et les registres sont à basculer). Ce qui en fait bien sûr un danger et l'origine de beaucoup de problèmes.
Une dernière remarque pour souligner que les threads sont subordonnées au processus qui les créé. La mort du processus entraîne la fin de tous les threads qu'il possède. Les processus n'ont pas de tels liens de subordination entre eux.
I-F. Calcul parallèle▲
Compte tenu de la diffusion massive des architectures
multi-coeurs et avec la mise en place des solutions GPGPU
(General-Purpose Processing on Graphics Processing Units ou
calcul générique sur un processeur graphique) de type CUDA,
le parallélisme monte en puissance dans les développements
actuels afin d'améliorer les performances des logiciels. Le
parallélisme est entendu dans ce contexte comme la
distribution des éléments d'un calcul sur un ensemble de données
(3)
dans différents coeurs afin d'améliorer significativement
les performances du calcul. Les objectifs sont distincts :
le parallélisme vise à améliorer le temps de calcul
en mettant en oeuvre un algorithme et des outils permettant
l'utilisation de plusieurs unités de calcul simultanément ;
le multithreading vise à proposer à l'utilisateur la simultanéité
au moins apparente du déroulement de différentes tâches sans
soucis d'amélioration des performances. Si le multithreading
peut s'accompagner d'une amélioration des performances du
logiciel, il ne s'agit pas de l'objectif premier.
Ces différences d'objectif se traduisent par une différence
dans la granularité des traitements qui font l'objet
de l'une ou l'autre technique. Avec le parallélisme, on
travaille au niveau d'un algorithme et d'un jeu de donnée. On
met l'accent sur l'algorithme mis en oeuvre et sur la façon
d'accéder aux données.
Avec le multithreading, on travaille au niveau d'un service
pouvant mettre en oeuvre plusieurs algorithmes ou au
moins des traitements plus complexes. L'accent est mis
sur ses interactions avec les autres threads du système dans
le cadre des problématiques de partage de ressources et
de synchronisation.
Pour autant, le multithreading demeure une solution pour
rendre ses programmes plus performants. La lecture
d'un fichier ou l'écriture à l'écran bloquent le thread courant
car l'accès aux périphériques est lent. Si une application
est découpée entre plusieurs threads, alors pendant que l'un
d'entre eux écrit sur un fichier, un autre peut prendre la
main et continuer à travailler. Même sur un système mono-coeur
cette approche accroît la performance globale de l'application.
Dans la classification de CallahanClassification de Callahan sur la problématique de la concurrence, le multithreading tel qu'il est abordé ici est défini par le pilier 1 : Réactivité et cloisonnement via des agents asynchrones ("Responsiveness and Isolation Via Asynchronous Agents"). Le parallélisme au sens de l'utilisation de plusieurs coeurs de calculs sur un ensemble de données correspond au pilier 2 : Débit et montée en charge des collections concurrentes ("Throughput and Scalability Via Concurrent Collections").
Différentes bibliothèques et techniques émergent pour distribuer des traitements sur différents coeurs de calculs. Citons : CUDA (GPGPU de NVidia), OpenCL (GPGPU du Khronos Group), OpenMP (consortium de constructeurs/éditeur de logiciel), TBB (Intel), QtConcurrent (QtSoftware, ex Trolltech).
Il est important de comprendre que ces différentes approches sont orthogonales entre elles : elles n'agissent pas au même niveau, elles n'ont pas les mêmes problématiques, elles n'utilisent pas les mêmes solutions. A l'heure où la course au GHz cède la place à celle des multicoeurs, le "free lunch" n'est possible que dans les applications qui savent utiliser ces différentes techniques. Le gain d'une application multithread n'est pas forcément proportionnel aux nombres de coeurs disponibles sur la plateforme. D'autres facteurs peuvent limiter ces gains en constituant des goulots d'étranglement : l'accès à des ressources plus lentes (fichiers, socket, ...), l'accès aux données mémoires disparates (cache L1 et L2 inutiles), un nombre de thread inapproprié par rapport aux nombres de coeurs, les caractéristiques des threads (leurs synchronisations, leur priorité, etc.).
I-G. Le multithread : pourquoi faire ?▲
Plusieurs scenarii accompagnent généralement la décision d'une
conception multithread : un traitement synchrone trop long, un
traitement asynchrone trop long,
une attente indéterminée ou encore un agent de monitoring.
Dans le premier cas, le multi threading est perçu comme une
réponse à un problème de performance. Un traitement long altère
la réactivité de l'interface aboutissant à une I.H.M. figée.
Le multithreading est alors envisagé pour informer l'utilisateur de
l'avancement d'une tâche. Cet avancement a pour double objectif
de faire patienter l'utilisateur et de lui signifier que le
logiciel est toujours actif. Ce cas s'accompagne
souvent par une interface réduite tant que la tâche n'est pas achevée :
toutes les fonctionnalités ne sont plus disponibles et un avancement
ou une animation maintient une I.H.M. active en attendant la fin du
traitement. Les exemples typiques de ce cas sont :
l'analyse d'un fichier, la transformation d'une donnée
(application d'un filtre à une image)...
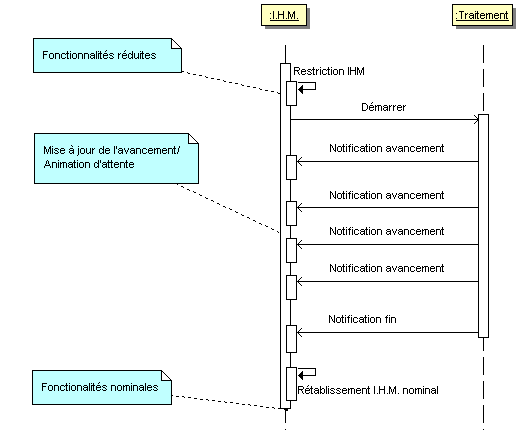
Le second cas concerne aussi une fonction suffisamment longue pour altérer la réactivité de l'I.H.M. La tâche n'empêche pas l'utilisateur de poursuivre son travail. Il s'agit bien d'offrir à l'utilisateur la possibilité d'effectuer plusieurs actions en même temps sans se soucier de l'achèvement de l'une avant d'entamer l'autre. L'I.H.M. est peu ou pas réduite et un avancement non intrusif peut informer de l'avancement de la tâche. Les exemples typiques de ce cas sont : l'impression, la sauvegarde des données...
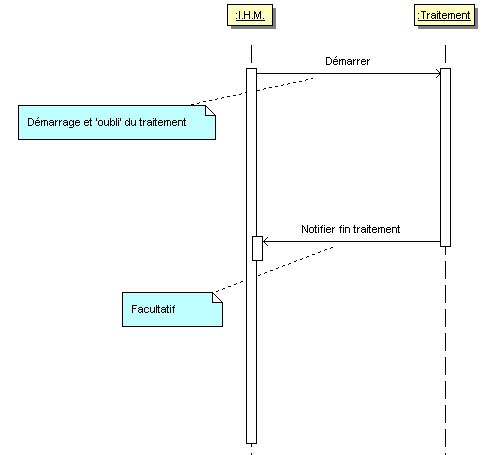
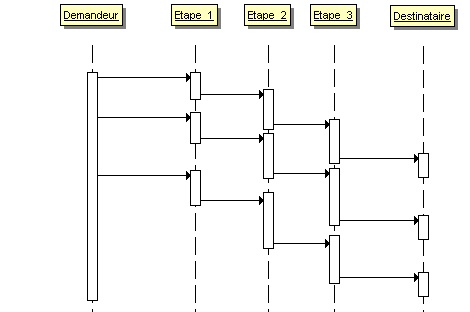
Ce second cas possède une déclinaison : le pipeline. Un traitement se décompose en plusieurs séquences, chacune d'entre elles est déroulée dans un thread séparé. Cela permet de cloisonner les différentes séquences et donne la possibilité de commencer un nouveau traitement alors que le précédent n'est pas encore achevé. Cette approche est appropriée dans les protocoles où un message passe par différentes couches entre la demande applicative et son envoi.
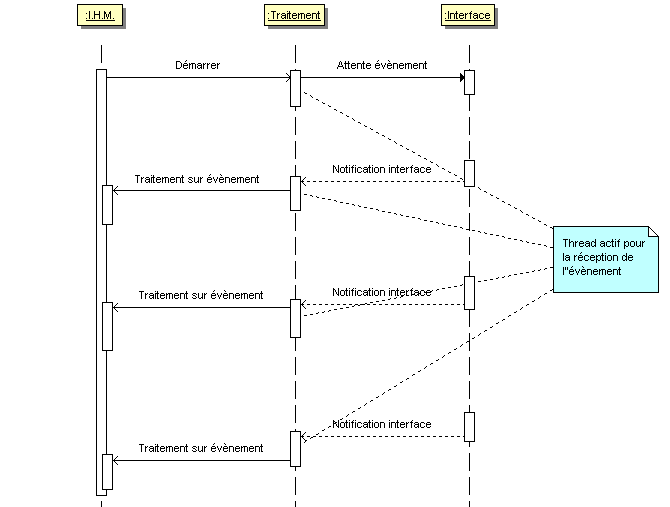
Le troisième cas apparaît lorsqu'on est en attente d'un événement sur une interface externe non liée à l'utilisateur. La bibliothèque ou le système d'exploitation offre une méthode permettant l'attente de l'événement souhaité mais cette méthode ne rend pas la main tant que cet événement ne survient pas. Entre temps, on souhaite maintenir l'I.H.M. active et permettre à l'utilisateur de continuer son travail. Les exemples typiques concernent l'attente d'un message réseau, d'un événement sur une carte série, d'un signal sur une carte d'acquisition...
Les applications clients/serveurs peuvent utiliser une variante du cas précédent dans l'implémentation du serveur. Un thread principal est dédié à l'écoute des nouveaux clients. Puis la gestion effective de chaque client est déléguée à un thread dédié. Les threads clients et le thread d'écoute n'ayant plus d'échange :
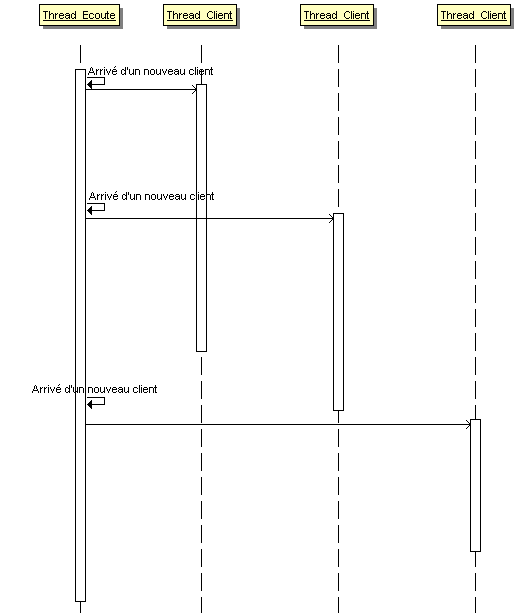
Le quatrième met en concurrence une application principale et un thread qui surveille cette application. L'application principale se déroule dans un ou des threads pendant que le thread de monitoring tourne à côté. Il peut interroger l'application sur son état, être notifié par l'application de modifications de son état ou encore avoir des séquences courtes d'échanges requête/ réponse. Les exemples se situent dans l'aide contextuelle, le log d'information, la mise en place d'un chien de garde (watchdog)...
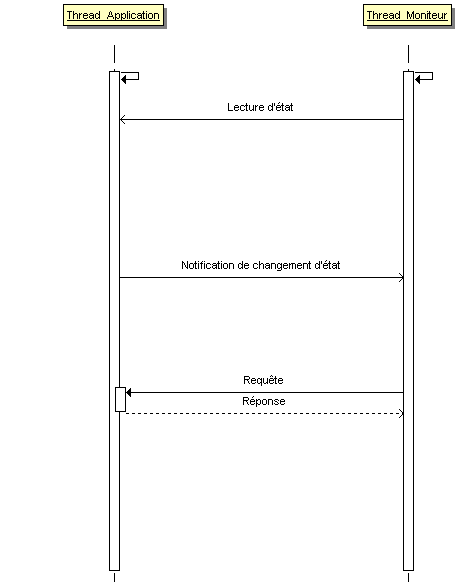
Les scénarii présentés mettent en concurrence un traitement et une I.H.M. En fait, ils peuvent être généralisés en mettant en concurrence un traitement non plus face à une I.H.M qui doit rester disponible mais avec un autre traitement critique qui doit rester réactif (Responsiveness dans la littérature anglo-saxone). Ainsi un serveur peut maintenir un thread principal pour l'écoute des nouvelles connexions et un ou des threads séparés pour la gestion des sessions avec les clients. Ce programme n'a pas d'I.H.M. mais la problématique reste identique : empêcher qu'une interface (celle qui attend les nouvelles connexions) ne soit bloquée à cause d'autres traitements (le dialogue avec les clients déjà connectés).
II. Les techniques alternatives▲
II-A. Connaître son framework▲
Les applications suffisamment complexes pour ressentir le besoin du multithreading sont souvent construites avec des frameworks offrant des services assez riches : MFC, Qt, wxWidgets, etc. Ces ateliers possèdent des mécanismes de notification par appel de callback ou par envoi de message pour des opérations liées à l'attente d'événements sur une interface spécifique. Ainsi, dans le cadre de projets réseaux, les MFC proposent la classe CAsyncSocket qui ne bloque pas sur l'envoi ou la réception d'un message. La spécialisation de OnReceive dans une classe dérivée de CAsyncSocket est appelée par l'atelier dans le contexte du thread courant dès lors que des données sont disponibles. De la même façon, wxWidgets émet des événements wxSOCKET_INPUT ou wxSOCKET_OUTPUT pour la réception ou l'émission de données. Ces mécanismes évitent d'avoir à gérer des réceptions ou des envois bloquants. Ces solutions sont à préférer pour au moins deux raisons. D'abord elles sont cohérentes avec le service proposé par le framework aboutissant naturellement à une architecture plus lisible dans ce cadre. Ensuite le multithreading induit une architecture logicielle plus complexe et fait émerger - comme nous allons le voir - des problèmes spécifiques : il ne faut jamais hésiter à opter pour des architectures simples garantissant moins de bug et facilitant les tâches de maintenance et d'évolution du logiciel.
Bien se documenter sur son framework ou sur la bibliothèque faisant émerger le besoin de multithreading.
II-B. OnIdle▲
Les framework d'I.H.M. sont construits autour de boîtes
aux lettres et d'échanges de messages entre les différents
objets entre eux suite à des événements internes ou à
une interaction avec l'utilisateur. Lorsqu'il ne se passe
rien, c'est à dire que l'utilisateur n'interagit pas
avec l'application et que celle-ci est stable, la plus part
de ces plateformes proposent un événement OnIdle.
Ceci offre la possibilité d'effectuer des traitements
pendant la période d'inactivité du logiciel.
Il faut bien comprendre qu'à l'échelle d'un processus
l'inactivité d'un logiciel est un événement courant.
Deux appuis touches successifs sur un clavier représentent
pour un processus deux événements 'rares' au milieu
d'une période assez calme.
Comment mettre en oeuvre cette technique ?
Pour les cas de traitement trop long, cela consiste à
créer un contexte et à atomiser le traitement
en opérations plus élémentaires. A chaque appel à
OnIdle, une opération élémentaire est déroulée et
le contexte actualisé. Le traitement se termine
dès que la dernière opération est exécutée.
Pour le cas d'attente d'un événement externe, la bibliothèque
utilisée peut permettre d'associer un timer à l'attente
de l'événement extérieure. Il suffit de positionner
un timer de zéro ou suffisamment petit et de regarder si le
retour est lié à l'expiration du timer ou à la réception
d'un signal.
Cette approche souffre principalement de ne
pas maîtriser à priori quand une séquence de OnIdle
va être déroulée. Si l'application est très sollicitée,
l'accomplissement de la tâche en est d'autant plus affecté.
Cette solution peut être mise en oeuvre lorsque l'achèvement
de la tâche de fond ne revêt pas un caractère important.
Le second scénario proposé ci-dessus cadre assez bien
avec cette solution puisque la tâche n'altère pas
le déroulement de l'application.
II-C. Utiliser un timer▲
L'utilisation d'un timer constitue une approche identique
à la précédente si ce n'est qu'on ne laisse pas l'environnement
décider de la fréquence de l'appel à notre traitement. L'idée
est d'armer un timer et d'appeler la méthode de traitement
à chaque fois que le timer claque. Les traitements
longs synchrones ou asynchrones sont comme précédemment
découpés en opérations plus petites et un contexte est
associé. A chaque déclenchement du timer, une opération
élémentaire est déroulée et le contexte est mis à jour.
Lorsque la dernière opération est terminée, le timer
est arrêté.
Pour le cas d'attente d'un événement externe,
il suffit d'interroger l'interface
en mode non bloquant à chaque fois que le timer se déclenche.
II-D. La boucle de message▲
Cette solution concerne spécifiquement le cas d'un traitement trop long que l'on souhaite synchrone avec une I.H.M. d'attente. Le problème souvent rencontré est de permettre à l'I.H.M. de se mettre à jour et de réagir à minima pendant toute la durée du traitement. L'idée est de découper le traitement en opérations élémentaires. Entre chaque opération, la pompe des messages est appelée de façon à vider les messages générés soit par le traitement soit par l'utilisateur. Cette solution est le symétrique de celle de OnIdle : ici, ce n'est pas le traitement qui est appelé dans le temps disponible entre deux messages, mais c'est la boucle de message qui est appelée entre deux opérations du traitement.
II-E. Le polling▲
L'appel régulier à une méthode permettant d'interroger l'état d'une interface s'appelle le polling. C'est souvent une technique alternative à l'utilisation des mécanismes de messages. L'application consiste alors à dérouler une boucle continuelle d'interrogation des interfaces (polling clavier, souris, réseau, etc.), suivi d'une séquence de mise à jour de l'état de l'application en fonction de l'état des interfaces.
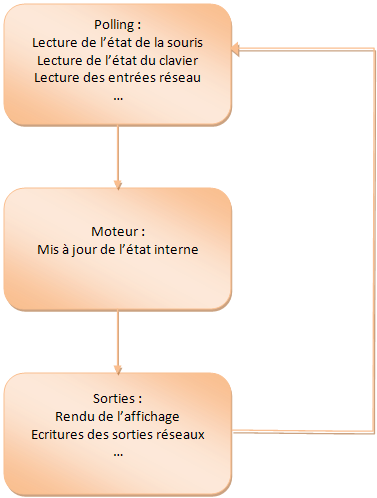
Cette méthode peut ne pas toujours être adéquate et aboutir à des pertes d'information. Si le système passe d'un état E0 à un état E1 puis revient à l'état initial E0 entre 2 séquences consécutives de polling alors la transition à l'état E1 est perdue.
II-F. Multithread collaboratif▲
Une application proposant une interface un tant soit peu riche va s'appuyer sur une architecture logicielle à base de messages/boîtes aux lettres (les windows), le traitement des messages et leur échange est orchestré par la boucle principale chargée de pomper les messages et les transmettre aux boîtes aux lettres concernées, déclenchant l'action attendues. Ce système construit autour d'objet boîtes aux lettres se sollicitant mutuellement par l'envoi de message pour réaliser leur service correspond assez bien à un système multithread collaboratif. Le contexte de chaque thread est porté par l'instance d'une la boîte au lettre (HWND/CWnd) et le changement de contexte nécessite que chaque boîte au lettre redonne la main à la pompe des messages. Si les objets ne communiquent entre eux que par échange de messages, le parallèle reste à mon sens pertinent.
III. Les problèmes▲
III-A. La situation de compétition : race condition▲
La situation de compétition ou race condition décrit un système dont le résultat est dépendant de l'ordre dans lequel sont effectuées certaines opérations. L'exemple le plus trivial apparaît lorsque plusieurs threads travaillent sur la même donnée sans synchronisation entre eux :
int variable;
void thread_1()
{
variable = 1;
}
void thread_2()
{
variable = 2;
}La valeur de variable dépend de l'ordre dans lequel les threads sont exécutés. Ce problème paraît évident, mais la situation de compétition apparaît sur des opérations simples et où on ne l'attend pas forcément :
int variable = 0;
void thread_1()
{
variable++;
}
void thread_2()
{
variable++;
}Quelle est la valeur de variable une fois thread_1 et thread_2 terminés ? Aucune idée ! Cela dépend plus subtilement de l'ordonnancement des threads. En effet, l'incrément (variable++) n'est pas une opération atomique. Pour s'en convaincre, il suffit de regarder le code assembleur de l'opération (code assembleur de Visual C++ Express 2008 en mode debug) :
mov eax,dword ptr [variable]
add eax,1
mov dword ptr [variable],eaxImaginons ce premier scénario :
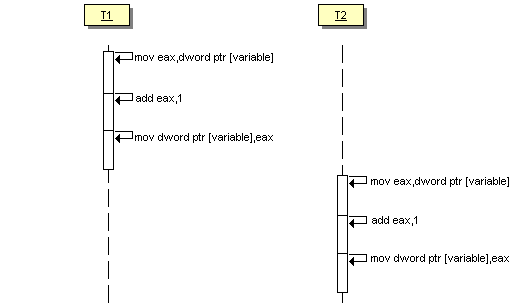
- Le premier thread prend la main :
- A l'entrée, variable vaut 0
- On charge dans le registre eax la valeur de variable : eax <- 0
- On ajoute 1 à eax : eax <- 1
- On copie la valeur de eax dans variable : variable <- 1
- Le second thread prend la main :
- A l'entrée, variable vaut 1
- On charge dans le registre eax la valeur de variable : eax <- 1
- On ajoute 1 à eax : eax <- 2
- On copie la valeur de eax dans variable : variable <- 2
Tout à l'air de fonctionner comme on aurait envie. Maintenant, regardons le scénario suivant :
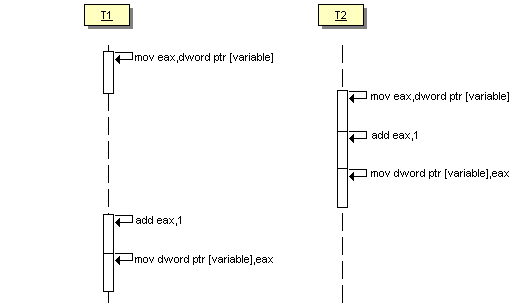
- Le premier thread prend la main :
- A l'entrée, variable vaut 0
- On charge dans le registre eax la valeur de variable : eax <- 0
- Le thread est suspendu : son registre est sauvegardé
- Le second thread prend la main :
- A l'entrée, variable vaut 0
- On charge dans le registre eax la valeur de variable : eax <- 0
- On ajoute 1 à eax : eax <- 1
- On copie la valeur de eax dans variable : variable <- 1
- Le premier thread récupère la main :
- On restaure les registres : eax <- 0
- On ajoute 1 à eax : eax <- 1
- On copie la valeur de eax dans variable : variable <- 1
Une fois les deux threads exécutés, variable vaut 1 !
Ces exemples doivent vous faire comprendre que si le problème se pose pour des opérations aussi simples, dès lors que les traitements sont complexes, il n'est plus possible de concevoir un comportement correct sans outils spécifiques pour synchroniser l'accès à des ressources partagées. C'est ce que nous verrons plus loin.
III-B. L'interblocage : le deadlock▲
Imaginons le scénario suivant. La porte de votre bureau se
déverrouille avec votre badge d'accès électronique.
Ce midi vous avez été déjeuné avec un collègue qui travaille
dans le bureau d'à-côté. En rentrant, vous vous rendez compte
que vous avez oublié votre badge dans le bureau de votre
collègue ... et pas de chance, votre collègue a oublié le sien dans votre bureau ! Vous ne pouvez déverrouiller votre bureau tant que votre collègue n'a pas déverrouillé sa porte mais votre collègue ne peut déverrouiller son bureau tant que vous n'avez pas déverrouillé votre porte. Vous ne pouvez plus qu'attendre
tous les deux sans rien faire : votre responsable va râler !
Vous avez un interblocage ou deadlock.
Le monde des threads est aussi fait de portes et de verrous.
Ces objets permettent de résoudre le problème précédent de
race condition. Deux threads qui souhaitent partager une
ressource utilisent ce système : le premier verrouille la
porte tant qu'il a besoin de la ressource.
Le second thread ne peut accéder à la ressource tant que
la porte est verrouillée. Il se met en attente. Il devient
clair maintenant qu'avec ce système l'interblocage peut se
produire entre deux threads qui partagent deux verrous
et attendent mutuellement l'ouverture de la porte verrouillée
par l'autre :
void thread_1()
{
attendre_porte_1_déverrouillée(); // 1.1
verrouiller_porte_1(); // 1.2
attendre_porte_2_déverrouillée(); // 1.3
verrouiller_porte_2(); // 1.4
traitement(); // 1.5
déverrouiller_porte_2(); // 1.6
déverrouiller_porte_1(); // 1.7
}
void thread_2()
{
attendre_porte_2_déverrouillée(); // 2.1
verrouiller_porte_2(); // 2.2
attendre_porte_1_déverrouillée(); // 2.3
verrouiller_porte_1(); // 2.4
traitement(); // 2.5
déverrouiller_porte_1(); // 2.6
déverrouiller_porte_2(); // 2.7
}L'exécution suivante provoque l'interblocage :
- 1.1
- 1.2
- 2.1
- 2.2
- 1.3
- 2.3
- -> deadlock !
Une déclinaison particulière de l'interblocage est le self deadlock. A priori, une fois une porte verrouillée, elle est interdite aux autres threads mais aussi au thread qui l'a verrouillée. Lorsque le même thread essaie de verrouiller une porte qu'il a déjà verrouillé, le blocage obtenu s'appelle un self deadlock
void thread_1()
{
attendre_porte_déverrouillée();
verrouiller_porte();
traitement();
déverrouiller_porte();
}
void traitement()
{
attendre_porte_déverrouillée();
verrouiller_porte();// self deadlock !
}Pour terminer sur ces deadlocks, signalons que les fonctions permettant d'attendre qu'une porte soit déverrouillée sont optimisées pour ne pas consommer inutilement des ressources systèmes. Lorsqu'un thread entre dans une telle attente, le système suspend le thread et ne lui donne plus de temps processeur tant que la porte est verrouillée. Une application de deux threads en interblocage ne consomme plus aucune ressource (temps processeur nul) et ne fait plus rien. Encéphalogramme plat___
III-C. L'interblocage actif : le live lock▲
Pour résoudre le problème du deadlock présenté ci-dessus,
les solutions présentent des fonctions d'attente associées
à une durée. Si la porte n'a pu être déverrouillée pendant
cette durée, alors un état d'échec est notifié à l'appelant
laissant celui-ci la possibilité de passer à autre chose. Ceci
peut permettre au moins à chaque thread de passer dans un mode
d'échec et à l'application de continuer à fonctionner. Mais
toute solution amène son propre cortège de problèmes
Reprenons notre situation précédente : vous travaillez au
premier étage et votre collègue au second. En rentrant de déjeuner
chacun part vers son bureau pas encore conscient de la catastrophe.
Arrivé devant votre porte, vous vous souvenez que vous avez
laissé votre badge chez votre collègue. Vous vous rendez à son bureau
par l'escalier. Ce dernier a eu la même démarche que vous, mais
a pris l'ascenseur : vous ne vous êtes pas croisé. Arrivé devant
son bureau, vous vous rendez compte que la porte est fermée
et décidez d'attendre cinq minutes le retour de votre collègue.
Ce dernier attend aussi devant votre porte. Les cinq minutes
écoulés, vous vous dites qu'il est trop bête de perdre ainsi
son temps, vous allez prendre un café et reviendrez ensuite en
pensant que votre collègue sera bien de retour à ce moment. Ce
dernier a le même raisonnement que vous, mais n'aimant pas le
café préfère aller discuter un instant avec un autre collègue.
De retour chacun vers la porte de l'autre, vous pestez et attendez
encore cinq minutes. A la fin de la journée, votre collègue et
vous même avez passé votre temps à vous agiter mais sans
pouvoir accéder à vos bureaux respectifs : c'est le live lock.
Une situation encore plus simple : vous attendez l'ascenseur, la
porte s'ouvre, exactement en face de vous une autre personne.
Vous esquissez un pas sur la gauche pour vous permettre de
vous croiser. Malheurs ! Elle a la même idée que vous et esquisse
aussi un pas sur sa droite se retrouvant inévitablement en face
de vous. Vous voilà tous deux parti pour une danse sans fin de
gauche à droite et de droite à gauche.
Le live lock à la différence du deadlock précédent
peut laisser croire que le logiciel continuer de fonctionner
car régulièrement les threads sont actifs et consomment
des ressources, mais les tâches n'avancent pas car ils sont
toujours en attente croisée :
void thread_1()
{
attendre_porte_1_déverrouillée(); // 1.1
verrouiller_porte_1(); // 1.2
while(FAILED(attendre_porte_2_déverrouillée(10 secondes)) // 1.3
{
déverrouiller_porte_1(); // 1.4
traitement_alternatif(); // 1.5
verrouiller_porte_1(); // 1.6
}
// ...
}
void thread_2()
{
attendre_porte_2_déverrouillée(); // 2.1
verrouiller_porte_2(); // 2.2
while(FAILED(attendre_porte_1_déverrouillée(10 secondes)) // 2.3
{
déverrouiller_porte_2(); // 2.4
traitement_alternatif(); // 2.5
verrouiller_porte_2(); // 2.6
}
// ...
}Un live lock correspond au séquencement suivant :
- 1.1
- 1.2
- 2.1
- 2.2
- 1.3 (attente de 10 secondes pour le thread 1)
- 2.3 (attente de 10 secondes pour le thread 2)
- 1.4
- 1.5
- 1.6
- 2.4
- 2.5
- 2.6
- 1.3 (attente de 10 secondes pour le thread 1)
- 2.3 (attente de 10 secondes pour le thread 2)
- 2.4
- 2.5
- 1.4
- 1.5
- 2.6
- 1.6
- 2.3 (attente de 10 secondes pour le thread 2)
- 1.3 (attente de 10 secondes pour le thread 1)
- ...
III-D. Famine (starvation)▲
La famine ou starvation est une généralisation
des problèmes d'interblocages : une tâche ne peut accéder
à une ressource pendant un temps indéterminé.
Dijkstra a le premier
mis en évidence ces problèmes d'accès aux ressources
partagées et Hoare l'a illustré par le problème du dîner
des philosophes. Imaginez cinq philosophes assis à une table ronde,
chacun a à sa gauche une fourchette.
Dans leur assiette : un plat de spaghettis.

Pour manger, un philosophe a besoin de deux fourchettes et il
ne peut prendre que celle qui est soit juste à sa gauche
soit juste à sa droite. Bien sûr, les philosophes n'échangent
pas entre eux. L'interblocage apparaît si tous les philosophes
s'emparent de leur fourchette de gauche et se mettent à attendre
celle de droite accaparée par le voisin.
D'autres stratégies peuvent conduire à situation
de famine d'un ou de plusieurs convives.
Dans un système avec priorité, un des threads peut ne
jamais accéder à un verrou car des threads plus prioritaires
l'auront toujours avant lui. Ceci peut devenir plus critique
si trois threads T1, T2 et T3 d'ordre de priorité croissante,
avec T1 attend une ressource verrouillée par T2 et T3 attend
une ressource verrouillée par T1. T3, le thread pourtant le
plus prioritaire, reste bloqué.
III-E. Endormissement (dormancy)▲
Une tâche peut passer dans un état suspendu : elle n'est alors plus éligible par l'ordonnanceur et ne reçoit donc pas de temps CPU pour s'exécuter tant qu'elle reste dans cet état. Une tâche passe dans un état suspendu :
- Implicitement lorsqu'elle attend qu'un verrou se libère et d'une façon général par tous les mécanismes d'attente proposés par le système ;
- Explicitement par des fonctions proposées par le système (Sleep).
On parle d'endormissement (dormancy) dès lors qu'une tâche reste dans cet état d'attente pendant un temps indéterminé. L'endormissement peut être lié à la famine (attente indéterminée d'une ressource) ou tout simplement à une erreur : la tâche est suspendue et jamais réveillée.
III-F. Réentrance et thread-safety▲
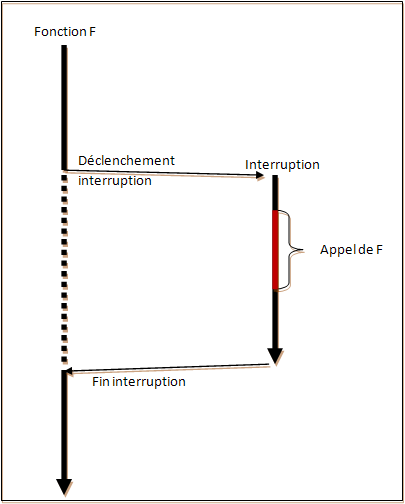
La réentrance est un terme apparu au départ dans la programmation système : une fonction est réentrante dès lors qu'elle peut être appelée avec des paramètres différents par une interruption alors qu'elle est déjà en cours d'exécution :
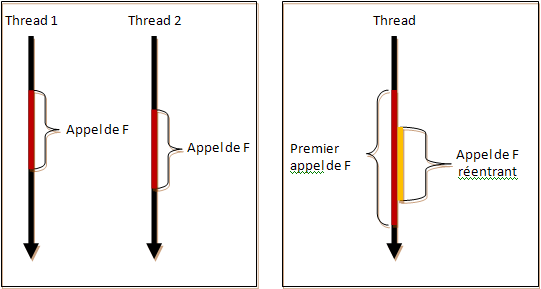
Dans le cadre de la programmation concurrente, une fonction réentrante est une fonction qui peut être exécutée correctement par plusieurs threads en même temps ou par le même thread avec des paramètres différents :
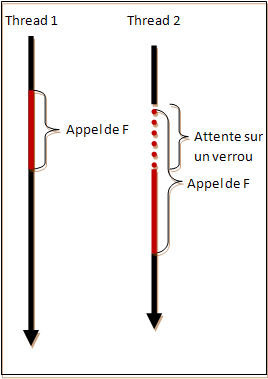
Une fonction est thread-safe si elle peut être appelée correctement par plusieurs threads distincts en même temps avec les mêmes paramètres. Grossièrement, une fonction thread-safe est une fonction qui se protège des problèmes de race-condition si nécessaire.
Par extension :
- Une classe est réentrante si toutes ses fonctions peuvent être appelées par plusieurs threads ou par le même threadsimultanément sur différentes instances.
- Une classe est thread-safe si toutes ses fonctions peuvent être appelées par plusieurs threads distincts simultanément sur la même instance.
En fait, une classe réentrante est une classe dont toutes
les fonctions ne s'appuient que sur l'état de l'objet et
des paramètres fournis. Elles ne dépendent dans leur déroulement
ou dans leur retour ni de variables statiques de la classe,
ni de variables statiques locales, ni de variables globales
et ne font appels qu'à des classes réentrantes ou des fonctions
libres réentrantes. La garantie de réentrance est articulée
autour des paramètres qui lui sont donnés.
Une classe est thread-safe dès lors qu'elle utilise des moyens
de synchronisation (verrous) pour l'accès aux ressources
partagées. Le thread-safety est garantie par l'implémentation
correcte de la classe.
Une fonction constante peut ne pas être réentrante : elle peut très bien s'appuyer sur des variables statiques ou globales.
Une fonction constante peut ne pas être thread-safe : elle peut accéder à un état en lecture seule mais celui-ci être modifié par ailleurs dans une autre fonction constante aboutissant à une situation de compétition.
L'utilisation d'une variable statique constante rompt la réentrance d'une fonction ou d'une classe. Le caractère constant ne suffit pas à se prémunir contre une exécution différenciée selon l'ordonnancement des threads : void fonction(int par_) { static const int first_par = par_; // ... }
La propriété thread-safe ne garantie pas la réentrance : une fonction peut s'appuyer sur un verrou non réentrant.
La réentrance ne garantie pas le caractère thread-safe : si on différencie le caractère réentrant du caractère thread-safe par le fait que le premier est considéré au regard d'appels avec des paramètres différents alors que le second suppose garantir l'appel pour des paramètres identiques, les deux notions deviennent orthogonales. Une classe peut très bien n'avoir que des fonctions s'appuyant uniquement sur l'état de l'instance et les paramètres fournis mais en aucun cas ne protégé l'accès à son état d'accès concurrent. Elle est bien réentrante mais n'est pas thread-safe.
IV. Les objets du multithreading▲
IV-A. Les threads▲
IV-A-1. Thread principal et threads secondaires▲
Les threads naissent libres et égaux en droit. Enfin, presque.
Une application contient toujours au moins un thread. Primus
inter pares, ce thread est désigné comme le
thread principal (main thread). Ce thread est créé par
l'environnement au lancement de l'application.
Les autres threads sont créés explicitement par
l'application. Ce sont des threads secondaires.
La mort du thread principal sonne le glas du processus le
contenant. Et ceci même s'il reste d'autres threads
secondaires encore actifs. Ceux-ci sont brutalement achevés
par l'O.S. sans aucune considération pour les ressources
qu'ils manipulent.
Cette distinction entre thread principal et thread
secondaire et cette particularité du premier à conditionner
la durée du processus est une spécificité de l'O.S.
(sous Windows par exemple) et n'est ni liée aux threads
en général ni aux différentes bibliothèques présentées
ci-après. Notez que la plateforme .Net par exemple ne
suit pas ce comportement : un processus créé sous .Net
reste actif tant qu'il reste de threads actifs même si
le thread de lancement est terminé.
(4)
Il en est de même en Java où la machine virtuelle Java
continue de tourner tant qu'il reste des threads actifs.
(5)
On peut supposer que des bibliothèques avec des couches
d'abstraction plus élevées peuvent encapsuler un
comportement identique. Ceci ne reste donc vrai que
sur certains O.S. et qu'avec des bibliothèques
d'abstraction assez proche de l'implémentation par
l'O.S. des threads.
IV-A-2. Threads I.H.M. et threads de travail▲
Le multithreading apparaît le plus souvent avec des applications
présentant une I.H.M. et souhaitant donner à l'utilisateur
l'impression que plusieurs fonctions s'exécutent en même temps.
On distingue alors deux types de thread : les threads I.H.M. et
les threads de travail. Les premiers interagissent
avec l'utilisateur : ils affichent des fenêtres, des boîtes
de dialogues, récupèrent les événements liés à la souris,
au clavier. Les threads de travail n'ont pas d'interaction
avec l'utilisateur. Ils sont aveugles à l'extérieur,
ne travaillent et n'interagissent qu'avec les éléments
internes de l'application. S'ils interagissent avec d'autres
interfaces (réseaux, disques durs, port série), ce n'est
pas avec un mécanisme de pompe de message.
Les threads I.H.M. vont se distinguer des threads de
travail par la présence d'une pompe de message chargée
de recevoir les messages et de les aiguiller vers la
bonne boîte aux lettres. Ce vocabulaire n'est pertinent
que pour les framework gérant l'I.H.M. et dont les
threads ne sont qu'une facette (M.F.C., wxWidgets, Qt).
Ces éléments ne sont pas pertinents pour des bibliothèques
plus ciblées sur les threads (Boost).
IV-A-3. Thread joignable et thread détaché.▲
IV-A-4. Qu'attend-on d'un type thread ?▲
IV-A-5. Attendre la fin d'un thread▲
redondant avec join ?
IV-A-6. Suspendre/Reprendre▲
sleep, yield
Suspend/Resume ?
IV-A-7. Thread Local Storage▲
IV-B. Coordonner les accès concurrent : les verrous▲
IV-C. Synchroniser les threads : condition variables et barrières▲
IV-C-1. Les condition variables▲
condition est une généralisation de événements à la windows.
un ou des threads en attente sur la condition, un thread
qui 'déclenche' la condition -> termine l'attente
d'un ou des threads.
IV-C-2. Les barrières▲
Les barrières permettent à plusieurs thread de se synchroniser à un point donnée (la barrière). Autre terme : rendez-vous.
IV-D. Récupérer le résultat d'un thread : les futures▲
Essentiellement en C++0x.
V. Quelques pattern de la programmation concurrente▲
A voir si intéressant à développer ici :
- Active Object
- Balking pattern
- Double checked locking pattern
- Guarded suspension
- Leaders/followers pattern
- Monitor Object
- Read write lock pattern
- Scheduler pattern
- Thread pool pattern
- Thread-Specific Storage
- Reactor pattern
VI. L'API windows Win32▲
VI-A. OnIdle▲
VI-B. Les timers▲
VI-C. Une boucle de message▲
VI-D. Les threads▲
VI-E. Les mutex▲
VI-F. Les sections critiques▲
VI-G. Les locks▲
Les locks win32.
Slim Reader/Writer (SRW) Locks de Vista
VI-H. Les événements▲
Evènements se rapprochent des conditions -> ConditionVariable sous Vista
VI-I. ...▲
InitOnce[XXX] ? Interlocked[XXX] ?
VII. Les MFC▲
VII-A. OnIdle▲
VII-B. Les timers▲
VII-C. Une boucle de message▲
VII-D. Les threads▲
VII-E. Les événements▲
VII-F. Les sections critiques▲
VII-G. Les mutex▲
VIII. wxWidgets▲
VIII-A. OnIdle▲
VIII-B. Les timers▲
VIII-C. Une boucle de message▲
VIII-D. Les threads▲
VIII-E. Les conditions▲
VIII-F. Les sections critiques▲
VIII-G. Les mutex▲
IX. QT▲
Voir avec Yan
X. Boost.Thread▲
X-A. Les threads▲
X-B. Les conditions▲
X-C. Les mutex▲
X-D. Les exceptions▲
X-E. Remarques▲
Utilisations des versions multi-thread des bibliothèques boost compilées.
XI. Les threads demain : C++0x▲
thread, mutex, lock, condition, atomic
XII. Références.▲
- 1 Présentation rapide du multitâche : http://fr.wikipedia.org/wiki/Multitâche
- 1 Présentation rapide des processus : http://fr.wikipedia.org/wiki/Processus_(informatique)
- 1 Présentation rapide des threads : http://fr.wikipedia.org/wiki/Processus_léger
- 3 Multithreading Tutorial : présente les concepts puis propose des pattern : http://paulbridger.net/multithreading_tutorial
- 5 Point d'entrés d'articles de Herb Sutter sur la concurrence : http://herbsutter.wordpress.com/ + http://www.gotw.ca/publications/
- 4 Systèmes répartis : http://krakowiak.developpez.com/cours/systeme-reparti/
- 3 Command pattern : http://www.ddj.com/database/184416612
- 5 Les piliers de la concurrence : http://www.ddj.com/hpc-high-performance-computing/200001985
- free lunch : http://www.gotw.ca/publications/concurrency-ddj.htm
- Dîner des philosophes http://fr.wikipedia.org/wiki/Dîner_des_philosophes GB : http://en.wikipedia.org/wiki/Dining_philosophers_problem
- 3 Tuto windows (chap 5 sur les threads) : http://bob.developpez.com/tutapiwin/
- FAQ Windows/Thread : http://windows.developpez.com/faq/win32/?page=processus
- 3 Article intéressant sur la prog des threads avec windows http://www.devarticles.com/c/a/Cplusplus/Multithreading-in-C/
- Un framework plus global : http://www.cs.wustl.edu/~schmidt/patterns-ace.html
- MSDN (MFC)http://msdn.microsoft.com/fr-fr/library/975t8ks0(VS.80).aspx
- MSDN (Process&thread) http://msdn.microsoft.com/en-us/library/ms681917(VS.85).aspx
- MSDN (IPC) http://msdn.microsoft.com/en-us/library/aa365574(VS.85).aspx
- MSDN (Dot net) : http://msdn.microsoft.com/en-us/library/hkasytyf.aspx
- Linux : http://linux.developpez.com/cours/alp/ en français : http://mtodorovic.developpez.com/linux/programmation-avancee/?page=page_4
- Boost.thread http://www.boost.org/doc/html/thread.html
- http://matthieu-brucher.developpez.com/tutoriels/cpp/boost/thread/
- C++0x : http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2009/n2857.pdf
- C++0x : http://www.devx.com/SpecialReports/Article/38883
- C++Ox : http://www.justsoftwaresolutions.co.uk/threading/multithreading-in-c++0x-part-1-starting-threads.html
- 3 Présentation des threads en Java/C# http://www.dotnetguru.org/articles/dossiers/threads/multithreading.htm
- Semaphore et mutex en java et deplhi http://mdalbin.developpez.com/tutoriels/general/semaphores/
- Thread et Communication en Java http://viennet.developpez.com/cours/java/thread/
- Programmation des Threads en Java http://alwin.developpez.com/tutorial/JavaThread/
- Java et la synchronisation http://rom.developpez.com/java-synchronisation/
- .NET et les threads http://drq.developpez.com/dotnet/articles/threads/
- http://systeme.developpez.com/cours/#parallelisme
- Introduction à la programmation parallèle http://vincentlaine.developpez.com/tuto/dotnet/parallel-extensions/
- Architecture multi-coeurs dans les moteurs 3D http://jeux.developpez.com/tutoriels/multithread/
- Une introduction à CUDA http://tcuvelier.developpez.com/gpgpu/cuda/introduction/
- bouml